
이번 글에서는 Coursera의 ETL and Data Pipelines with Shell, Airflow and Kafka (IBM) 1주차 강의를 정리합니다.
이 강좌는 ETL 및 ELT 데이터 파이프라인에 대해 학습하며, Airflow와 Kafka 등을 이용해 이를 배우게 됩니다.
1주차에서는 데이터 처리 기술에 대해 공부하며 ETL과 ELT 개념을 학습하고, 둘의 차이는 무엇인지에 대해 알아봅니다.
또한 ETL에서 ELT로 변화하게 되는 이유 등에 대해서도 학습할 수 있습니다.
1. 데이터 학습 목표
- ETL 프로세스가 어떠한 것인지 학습
- ELT 프로세스가 왜 최근 등장하고 있는 트렌드인지 학습
- 데이터를 Extraction 하고, Loading 하는 방법을 학습
- Batch Loading과 Stream Loading에 대해서 학습
2. ETL과 ELT
- ETL (Extraction, Transformation, Loading)
- ETL은 데이터를 수집하고, 준비하는 자동화 된 데이터 파이프라인 엔지니어링 방법론. 이를 통해 향후 데이터 웨어하우스나, 데이터 마트 같은 분석 환경에서 사용할 수 있도록 도움. 즉, 여러 소스의 데이터를 큐레이팅 해서 통합된 데이터에 맞추는 프로세스
- Extration: 하나 이상의 소스에서 데이터를 읽거나 얻는 과정
- 데이터에 대한 액세스를 구성하고, 애플리케이션으로 읽는 것 (일반적으로 자동화 되어 있음 - 크롤링 등)
- Transformation: 데이터를 의도된 용도에 맞게 변환하는 과정 (Data Wrangling)
- Cleaning, Filtering, Joining, Feature Engineering, Formatting and data typing 등
- Loading: 변환된 데이터를 가져와 새 환경에 로드하는 과정 (데이터베이스, 데이터 웨어하우스, 데이터 마트)
- 이 과정의 핵심 목표는 수집된 데이터를 쉽게 사용할 수 있도록 하는 것 (대시보드, 리포트 등에 활용)
- ELT (Extraction, Loading, Transformation)
- ELT는 ETL과 유사하지만, 순서가 조금 다른 데이터 파이프라인 엔지니어링 방법론. ELT는 데이터가 수집된 그대로 대상 환경에 직접 로드하고, 데이터 레이크 환경 등에서 사용자가 원하는대로 변환해서 사용하게 됨.
- Extraction: 데이터를 얻는 과정
- Loading: Raw data를 있는 그대로 사용하여 로드하는 과정
- Transformations: 사용자의 의도 및 요구대로 데이터를 변환시키는 과정
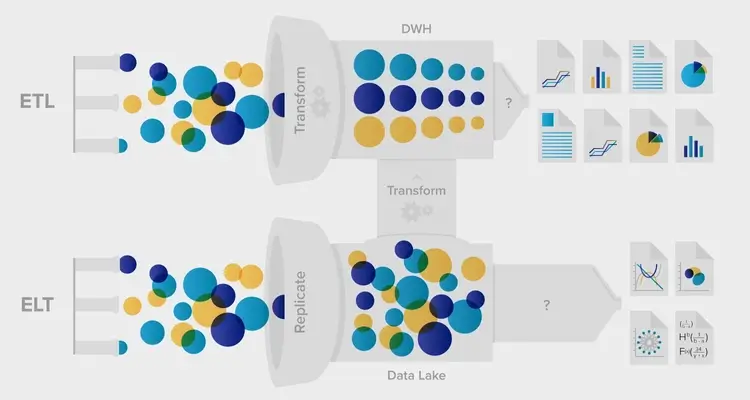
- ELT 방법이 등장하게 된 이유로는 빅데이터를 다루는 과정에서 빠르게 발전하고 있는 Cloud computing을 통해 ELT 방법론으로 데이터 이동과 처리를 면확히 구분할 수 있음. 또한 Raw 데이터를 적재한 후, 작업하기 때문에 정보 손실이 없다는 점도 장점 중 하나
- ETL과 ELT 비교: 최근에는 ETL에서 ELT로 변화되고 있는 추세
- ETL에서의 변환은 파이프라인 내에서 발생하는데, ELT에서는 파이프라인과 분리되어 동작. 따라서 ELT 방법에서는 Raw data 자체를 보호하며, 필요에 따라 데이터를 변환시켜 사용할 수 있음
- ETL은 고정적인 프로세스이지만, ELT는 유연성을 가지고 있다는 특징이 있음
- ETL에서는 전통적으로 구조화 된 관계형 데이터를 처리하기 때문에 확장성 등에서 문제가 발생할 수도 있는데, ELT에서는 모든 종류의 구조화 및 비구조화 데이터를 처리할 수 있음
- ETL 파이프라인은 수정하는데 시간과 노력이 필요하지만, ELT에서는 더 민첩하게 대처할 수 있음
3. 데이터 Extraction 기술
- OCR: 종이 문서 등에서 텍스트를 스캔
- ADC Sampling: 아날로그 오디오 녹음 및 신호를 디지털화
- CCD Sampling: 이미지를 캡쳐하고 디지털화
- 이메일, 휴대폰, 설문 등을 통해 얻은 통계 데이터 및 사용자 로그, 쿠키
- 웹 크롤링, API, 데이터베이스 쿼리
- Edge computing, 의료기기를 통한 데이터 획득
4. 데이터 Transformation 기술
- 응용 프로그램에 맞게 데이터 형식을 지정하는 과정
- Data typing, Data structuring (JSON, XML, CSV)
- Anonymizing, Encrypting (암호화 및 익명화)
- Cleaning, Normalizing, Filtering, Sorting, Aggregating, Binning, Joining
Schema-on-write는 ETL에서 사용되는 일반적 접근으로, 로드하기 전에 정의된 스키마를 준수해야 하는 것. 안전성 있게 데이터를 일관되게 구조화할 수 있지만, 다양성을 제한할 수도 있음Schema-on-read는 ELT 접근 방식과 관련 있고, 여기서 스키마는 Raw data에 적용. 엄격한 절차가 없기 때문에 잠재적으로 더 많은 데이터에 접근할 수 있음- 일반적으로 Raw data는 변환된 데이터보다 훨씬 큰데, ETL에서는 변환 과정에서 일부 데이터를 손실하게 될 수 있음. 하지만 ELT에서는 데이터를 그대로 복사하여 정보를 손실시키지 않음
5. 데이터 Loading 기술
- Full: 초기 기록 전체를 데이터베이스에 로드. 하나의 큰 배치로 데이터를 로드
- Incremental: 새로운 데이터를 삽입하거나, 이미 로드된 데이터를 업데이트
- Scheduled: 주기적으로 데이터 로드를 예약
- On-demand: 요청 시, 필요에 따라 데이터 로드
- Batch and Stream: 데이터를 일괄적으로 로드하거나, 스트리밍 (실시간 처리)
- Push and Pull: 데이터가 서버로 푸시되거나, 서버에서 클라이언트로 푸시
- Parallel and Serial: 병렬 로드, 직렬 로드
6. 참고 내용
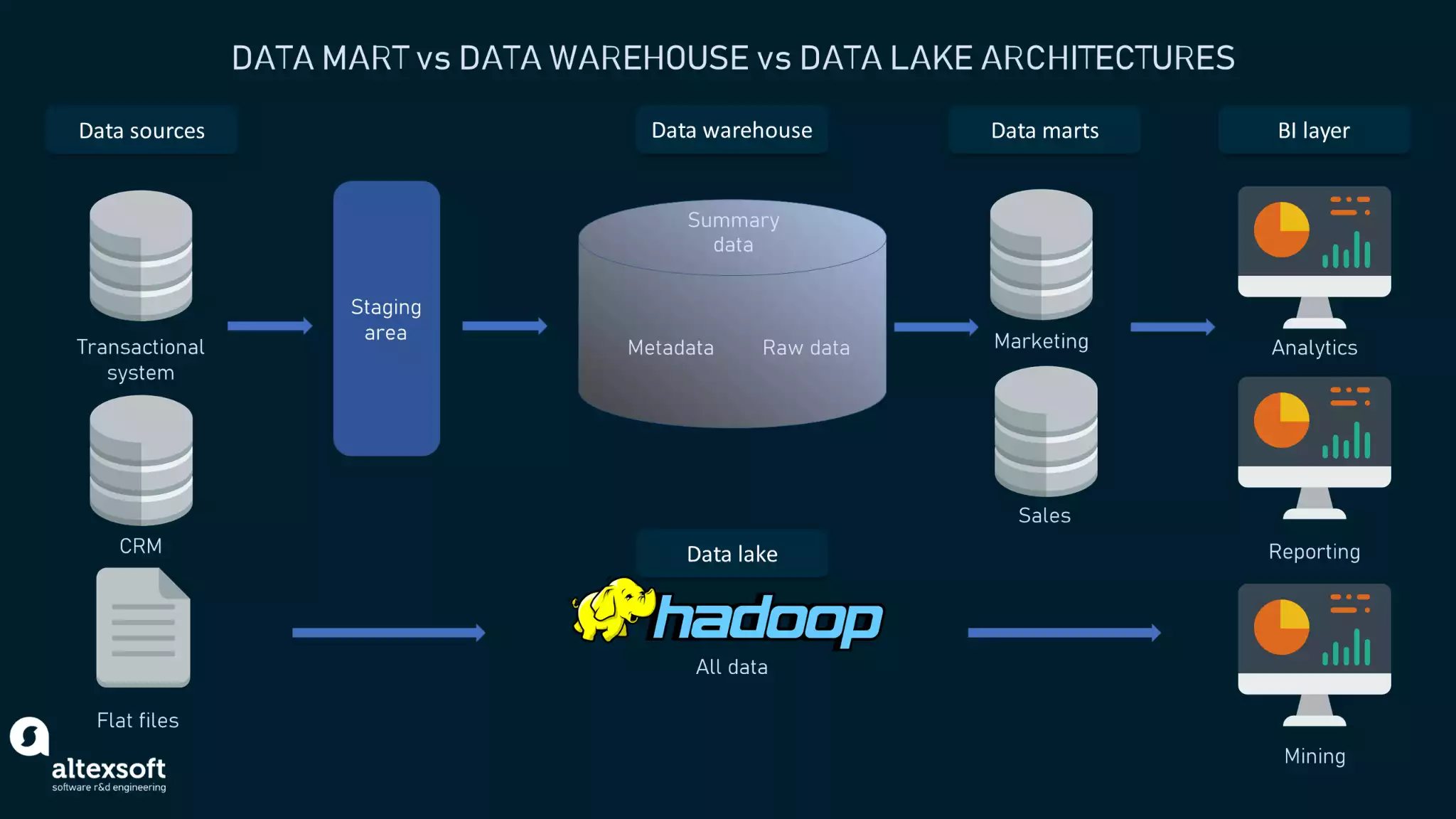
- Data Warehouse (DW): 의사결정에 도움을 주기 위해 분석 가능한 형태로 변환된 데이터가 저장된 중앙 저장소
- Data Lake: 사전에 정의된 구조 없이 방대한 양의 원시 데이터가 그대로 저장 (모든 데이터에 대한 중앙 리포지토리)
- Data Mart: 영업, 재무, 마케팅 등 단일 주제 등에 중점을 둔 단순한 형태의 데이터 웨어하우스
- 데이터 파이프라인을 통해 순차적으로 공급되거나 파이프 되는 데이터의 패킷
- 이상적으로는 세 번째 패킷이 수집이 될 때까지 세 개의 ETL 프로세스가 모두 서로 다른 패킷에서 동시에 실행

- 워크플로의 세부 사항을 개별 작업 사이의 종속성으로 분류하게 되면, 복잡성을 제어할 수 있음
- Apache Airflow 같은 워크플로 오케스트레이션 도구가 이러한 역할을 수행
- Airflow는 DAG (Directed Acyclic Graph)로 워크플로를 나타냄 (그림 참고)
- Airflow 작업은 연산자라고 하는 미리 정의된 템플릿을 사용하여 표현
- 이 연산자에는 Bash 실행을 위한 Bash 연산자와 Python 실행을 위한 Python 연산자가 포함
- 그렇기 때문에 ETL 파이프라인 및 기타 여러 종류의 워크플로를 프로덕션에 배포하는데 유용
- 아래 그림에서 녹색 상자는 개별 작업을 나타내고, 화살표는 작업 간의 종속성을 나타냄
