이번 글에서는 Coursera의 ETL and Data Pipelines with Shell, Airflow and Kafka (IBM) 2주차 강의를 정리합니다.
이 강좌는 ETL 및 ELT 데이터 파이프라인에 대해 학습하며, Airflow와 Kafka 등을 이용해 이를 배우게 됩니다.
2주차에는 데이터 파이프라인에 사용되는 도구와 기술에 대해 공부하며, Bash 스크립트와 일괄 및 스트림 처리를 배웁니다.
1. 데이터 학습 목표
- ETL의 각 단계에서 일어나는 일을 요약
- ETL 파이프라인의 중요성과 작동 방식 설명
- Shell 스크립트를 통해 ETL 파이프라인 구현 방법 요약
- 주요한 데이터 파이프라인 프로세스 설명
- 배치 및 스트리밍 데이터 파이프라인에 대해 학습
2. Shell 스크립트
- Shell은 유닉스 계열 운영 체제를 위한 강력한 사용자 인터페이스
- 명령을 해석하고, 다른 프로그램을 실행시킬 수도 있음
- 파일, 유틸리티 및 응용 프로그램에 대한 액세스를 가능하게 하며, 대화식 스크립팅 언어
- Shell을 통해 작업을 자동화할 수도 있음

3. 데이터 파이프라인
- 데이터 파이프라인 개념은 광범위 하게 적용되는데, 순차적으로 연결된 일련의 프로세스라고 할 수 있음
- 한 프로세스의 출력은 다음 프로세스에 대한 입력으로 전달
- 데이터를 이동하거나 수정하는 파이프라인 (데이터를 추출하여 전달하는 시스템)
- 데이터 파이프라인의 길이는 데이터 파이프라인에 걸리는 시간을 뜻함. 성능과 관련한 고려사항은 다음과 같음
- 대기 시간: 단일 작업에 걸리는 총 시간 (대기 시간은 개별 시간의 합으로 각 처리 단계에서 소비)
- 처리량: 단위 시간 당 파이프라인을 통해 얼마나 많은 데이터를 공급할 수 있는지를 뜻함
- 데이터 파이프라인 프로세스의 공통 단계
- 하나 이상의 데이터 소스에서 데이터를 추출
- 추출된 데이터를 파이프라인으로 수집
- 파이프라인 내에서 선택적으로 데이터 변환 후 최종 로드
- 실행할 작업을 예약하거나, 트리거를 걸어주는 매커니즘
- 전체 워크플로 모니터링 및 원활하게 실행 되도록 필요한 유지 관리, 최적화
- 작업에 걸리는 시간, 시간에 따라 처리되는 데이터 양, 과부하 등으로 인한 오류 및 장애 등
- 이벤트 로깅 시스템을 통해 특정 이벤트 (오류)가 발생시 관리자에게 알려주도록 함
- Load Balanced Pipelines
- 한 단계가 데이터 패킷에 대한 프로세스를 완료했을 때, 대기열에 있는 다음 패킷을 사용
- 파이프라인이 작동하는 동안 스테이지를 유휴 상태로 두지 않음
- 즉, 모든 단계에서 패킷을 처리하는데 동일한 시간이 소요되어야 한다는 것 (병목 현상이 없음)
- 하지만 시간 및 비용 등을 고려하면, 파이프라인이 완벽하게 로드 밸런싱 되지는 못함
- 거의 항상 데이터 흐름에서 병목 현상이 있는 단계가 있다는 것
- 이 병목 현상이 있는 단계를 병렬화할 수 있다면, 속도를 더 높일 수 있을 것
- 데이터 파이프라인 도구 및 기술
- Python의 Pandas 라이브러리
- Excel 또는 CSV 스타일의 테이블 형식 데이터 처리 가능
- 하지만 빅데이터로 확장하는데는 제한적. 데이터 프레임 조작은 메모리 내에서만 가능하기 때문
- 유사한 라이브러리로는 Vaex, Dask, Spark 등이 있음
- Apache Airflow
- Python 프로그래밍 언어를 기반으로 하는 오픈 소스 데이터 파이프라인 플랫폼
- 데이터 파이프라인 워크플로를 프로그래밍 방식으로 작성, 예약, 모니터링 가능
- AWS를 포함한 대부분의 클라우드 플랫폼과 통합
- Talend
- 또 다른 오픈소스 데이터 파이프라인 개발 및 배포 플랫폼
- 빅데이터 마이그레이션, 데이터 웨어하우징, 프로파일링 지원
- 협업, 모니터링, 스케줄링 기능 포함. 그리고 파이프라인을 생성할 수 있는 GUI 존재
- AWS Glue
- 분석을 위해 데이터를 쉽게 준비하고 로드할 수 있음
- 데이터 소스를 크롤링하여 데이터 형식을 검색
- 데이터를 저장할 스키마를 제안하고, AWS 콘솔을 이용해 ETL 작업을 빠르게 생성 및 실행 가능
- Panoply
- ETL 보다는 ELT에 초점을 맞추고, 코드 없이 데이터를 연결 및 통합 할 수 있음
- SQL 베이스로 데이터를 볼 수 있고, 데이터 파이프라인을 최적화 하는 대신 분석에 집중하도록 함
- Tableau나 Power BI 같은 대시보드 및 BI 도구와 통합 가능
- Streaming 데이터 파이프라인 도구로는 Storm, Spark, Kafka 등이 있음
- Python의 Pandas 라이브러리
4. Batch & Streaming, Micro-batch & Hybrid Lambda 파이프라인
- Batch Data Pipeline
- 데이터를 하나의 큰 단위로 추출하고 운영할 때 사용
- 주기적으로 작동 (Hours, Days, Weeks 등)
- 트리거를 기반으로 시작할 수도 있음 (예를 들면, 소스에 누적되는 데이터가 일정 크기에 도달했다면 실행)
- 최신 데이터에 의존하지 않는 경우, 정확성이 중요한 경우에 적합
- 주기적인 데이터 백업, 거래내역 로딩, 고객 주문 및 청구 처리, 중장기 매출 예측, 일기 예보 등
- Streaming Data Pipeline
- 데이터 패킷을 연속적으로 빠르게 수집 (예를 들면, 개별 신용 카드 거래, 소셜 미디어 활동 등)
- 레코드 또는 이벤트가 발생하는 즉시 처리 (거의 실시간으로 작동)
- 소셜 미디어 피드 및 감성 분석, 사기 탐지, 사용자 행동 분석, 타겟 광고, 주식 시장 거래, 실시간 추천 등
- Micro-batch Data Pipeline
- 배치 크기를 줄이고, 개별 배치 프로세스의 새로고침 빈도를 높여서 실시간으로 처리할 수 있음
- 로드 밸런싱에 도움이 되어서 전체 지연 시간을 줄일 수 있음
- 변환 과정에서 매우 짧은 데이터 기간만 필요한 경우에 유용
- Batch와 Streaming 방법에서는 Accuracy와 Latency에 대한 Trade-off가 존재
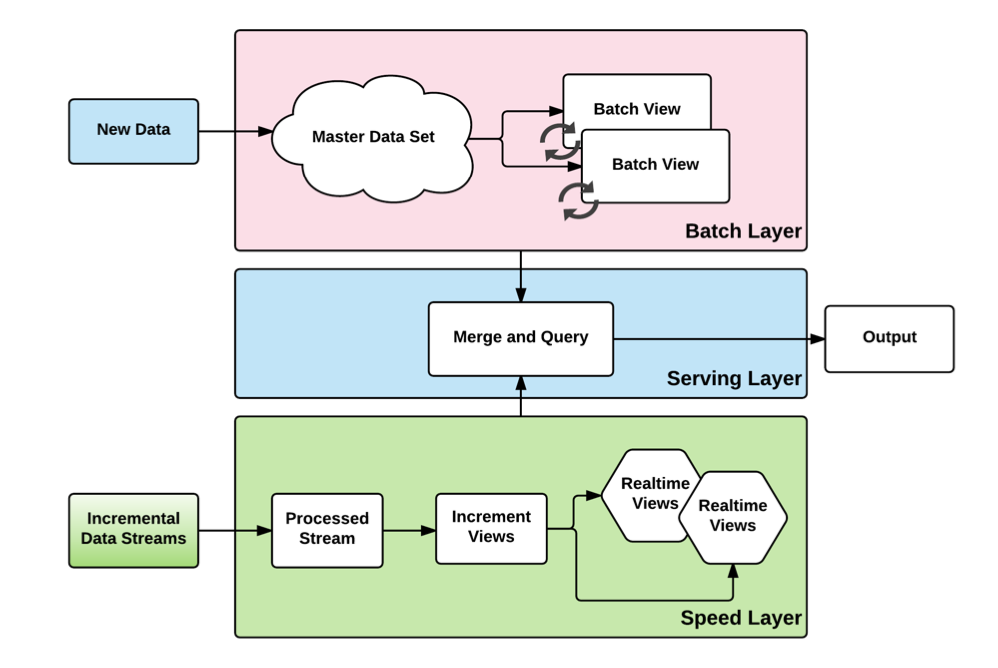
- Lambda Architecture
- 빅데이터를 처리하도록 설계된 하이브리드 아키텍쳐로 Batch와 Streaming 방법을 결합한 것
- 히스토리 데이터는 Batch layer로, 실시간 데이터는 Speed layer로, 그 후 두 계층이 Serving layer로 통합
- 정확성과 속도를 목표로 할 때 이 아키텍쳐를 사용
5. 참고 내용
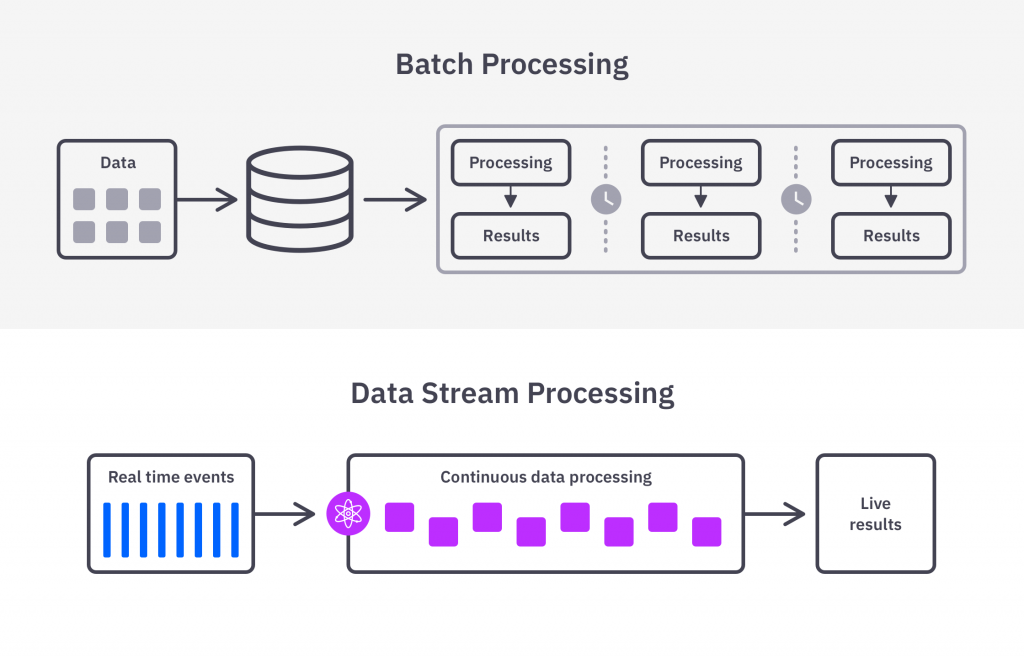
- Batch Processing (일괄 처리)
- 안정적이고 확장 가능한 데이터 인프라를 구축하는 데 중요한 단계 (일괄 처리 알고리즘 MapReduce)
- 설정된 시간 간격 동안 저장소에 데이터의 묶음(batch)을 로드하며, 일반적으로 사용량이 적은 업무 시간에 예약
- 대용량 데이터에 대한 작업으로 전체 시스템에 부담을 줄 수 있는 작업이 다른 워크로드에 미치는 영향을 최소화
- Streaming Processing (스트리밍 처리)
- 데이터를 지속적으로 업데이트 해야 할 때 활용
- 데이터가 생성되는 즉시 연속 스트림을 처리하는 것 (실시간 분석)
- Load Balancing (로드 밸런싱): 서버에 가해지는 부하 (로드)를 분산 (밸런싱) 해주는 장치 또는 기술
- Round Robin 방식: 서버에 들어온 요청을 순서대로 돌아가며 배정하는 방식
- Weighted Round Robin 방식: 각 서버마다 가중치를 매겨서, 가중치가 높은 서버에 요청을 우선적으로 배분
- IP Hash 방식: 클라이언트의 IP 주소를 특정 서버로 매핑하여 요청을 처리하는 방식
- Least Connection 방식: 요청이 들어온 시점에 가장 적은 연결 상태를 보이는 서버에 우선적으로 배분
- Least Response Time 방식: 서버의 현재 연결 상태와 응답시간을 모두 고려하여 트래픽을 배분

- Lambda Architecture (람다 아키텍쳐)
- Batch Layer: 데이터 조회 요청에 걸리는 시간을 최소화 하기 위해 배치를 이용해 데이터를 미리 계산
- Batch Layer의 저장소에서는 Raw 데이터를 보관
- Batch 뷰의 데이터가 부정확 할 때 복구 할 수 있음
- 이 단계에서는 Apache Hadoop을 사용
- Speed Layer: 배치가 도는 간격 사이에서는 데이터 조회가 불가능하므로, 배치 레이어에서 생기는 갭을 채움
- 이 단계에서는 Apache Storm, SQLstream, Apache Spark를 사용
- Serving Layer: 배치 레이어와 스피드 레이어의 출력을 저장
- Batch Layer: 데이터 조회 요청에 걸리는 시간을 최소화 하기 위해 배치를 이용해 데이터를 미리 계산