이번 글에서는 Coursera의 ETL and Data Pipelines with Shell, Airflow and Kafka (IBM) 4주차 강의를 정리합니다.
이 강좌는 ETL 및 ELT 데이터 파이프라인에 대해 학습하며, Airflow와 Kafka 등을 이용해 이를 배우게 됩니다.
4주차에는 Kafka를 이용해서 스트리밍 파이프라인을 구축하는 방법에 대해 공부합니다.
1. 데이터 학습 목표
- Kafka가 이벤트 스트리밍 플랫폼 (ESP)으로 작동하는 방식 학습
- Kafka의 핵심 구성 요소 학습
- Kafka의 Stremas API가 무엇이고, 장점은 무엇인지 등에 대해 학습
- Kafka-python 클라이언트를 통해 Kafka 서버에서 작업 실행시켜보기
2. 분산 이벤트 스트리밍 플랫폼
- Event 라는 것은 주목할 만한 일이 일어나고 있다는 것을 의미
- Event Streaming 맥락에서, Event는 시간이 지남에 따라 엔티티의 관찰 가능한 상태를 설명하는 데이터 유형
- 자동차의 GPS 좌표, 방의 온도, 환자의 혈압 측정, 애플리케이션에서 RAM 사용량 등
- Event는 특별한 데이터의 타입으로 형식이 서로 다른데, 일반적인 3가지는 다음과 같음
- Primitive (원시 유형): 일반 텍스트, 숫자, 날짜 등
- Key-value Pairs: List, Tuple, JSON, XML, Bytes 등
- Key-value with a Timestamp: 이벤트를 타임 스탬프와 연결하여 시간에 민감하게 표현
- Event Source와 Event Destination 사이의 연속적 이벤트 전송을
Event Streaming이라고 함- Event Source에는 Sensors, Devices, Applications 등과 같이 데이터를 만드는 대상
- Event Destination는 File Systems, Databases 등과 같이 Event Source가 전송되는 대상
- 실제로, Event Streaming은 다양하고, 분산된 Event Source와 Destination으로 복잡한 문제
- 데이터 전송 파이프라인의 프로토콜은 다음과 같은 것들이 있음
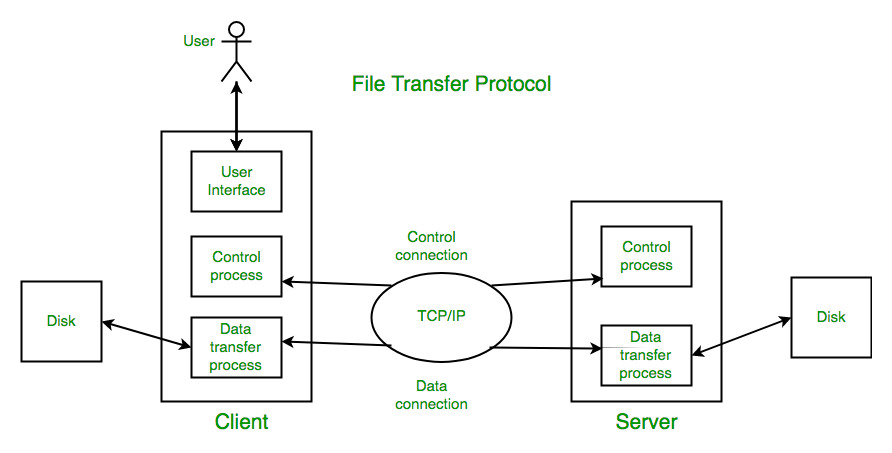
- FTP: File Transfer Protocol
- HTTP: Hypertext Transfer Protocol
- JDBC: Java Database Connectivity
- SCP: Secure Copy
- 또한 Event Destination은 동시에 Event Source가 될 수도 있음
- 다양한 Event Source와 Destination을 처리하기 위해서는,
ESP (Event Stream Platform)을 사용해야 함
- 데이터 전송 파이프라인의 프로토콜은 다음과 같은 것들이 있음
- ESP (Event Stream Platform)
- Event Source와 Destination 사이에서 중간 계층 역할을 하면서 이벤트 기반 ETL을 처리하기 위한 인터페이스
- 따라서 Event Source를 개별 Event Destination으로 전달하지 않고, ESP로 전달
- Event Destination은 ESP에 subscribe만 하고, 개별 Event Source로 받지 않고, ESP에서 데이터를 consume
- 아래 그림에서는 Event Source를 Producer로, Event Destination을 Consumer로 표현
- Popular ESP는 Kafka, Kinesis, Flink, Spark, Storm 등이 있음

- Common Components of an ESP
- Event Broker: ESP에서의 Core Component로, Ingester, Processer, Consumpution을 포함
- Ingester: 다양한 Event Sources로부터 Event를 효과적으로 받을 수 있도록 설계
- Processer: (De) Serializing, (De) Compressing, Encryption 등 데이터에 대한 작업 수행
- Consumpution: 이벤트 저장소에서 이벤트를 검색해 이벤트를 효율적으로 배포
- Event Storage
- Analytics and Query Engine
- Event Broker: ESP에서의 Core Component로, Ingester, Processer, Consumpution을 포함
3. Apache Kafka
- Kafka는 포괄적인 플랫폼이면서 많은 애플리케이션 시나리오에서 사용 가능
- 원래 Kafka는 사용자의 키보드를 통한 검색, 마우스 클릭, 검색 등과 같이 사용자의 활동을 추적하기 위한 것
- 하지만 지금은 하드웨어 및 소프트웨어 모니터링, 센서, GPS 등과 같이 Metric-Streaming에도 적합
- Kafka를 이용하여 중앙 저장소에 로그를 수집하고 통합 할 수도 있음 (거래내역을 다루는 은행, 보험 등에서 사용)
- 즉, Kafka를 통해 많은 양의 데이터를 처리할 수 있고, 신뢰할 수 있는 데이터 전송 서비스를 구축할 수 있음
- 모든 이벤트들은 Kafka를 통해 수집되고, 저장 및 소비가 가능
- 데이터 저장, 온오프라인 데이터베이스로의 이동, 백업, 실시간 처리, 분석, 대시보드, AI 등
- Email, 텍스트 메시지 등과 같이 Notification을 생성할 수도 있음

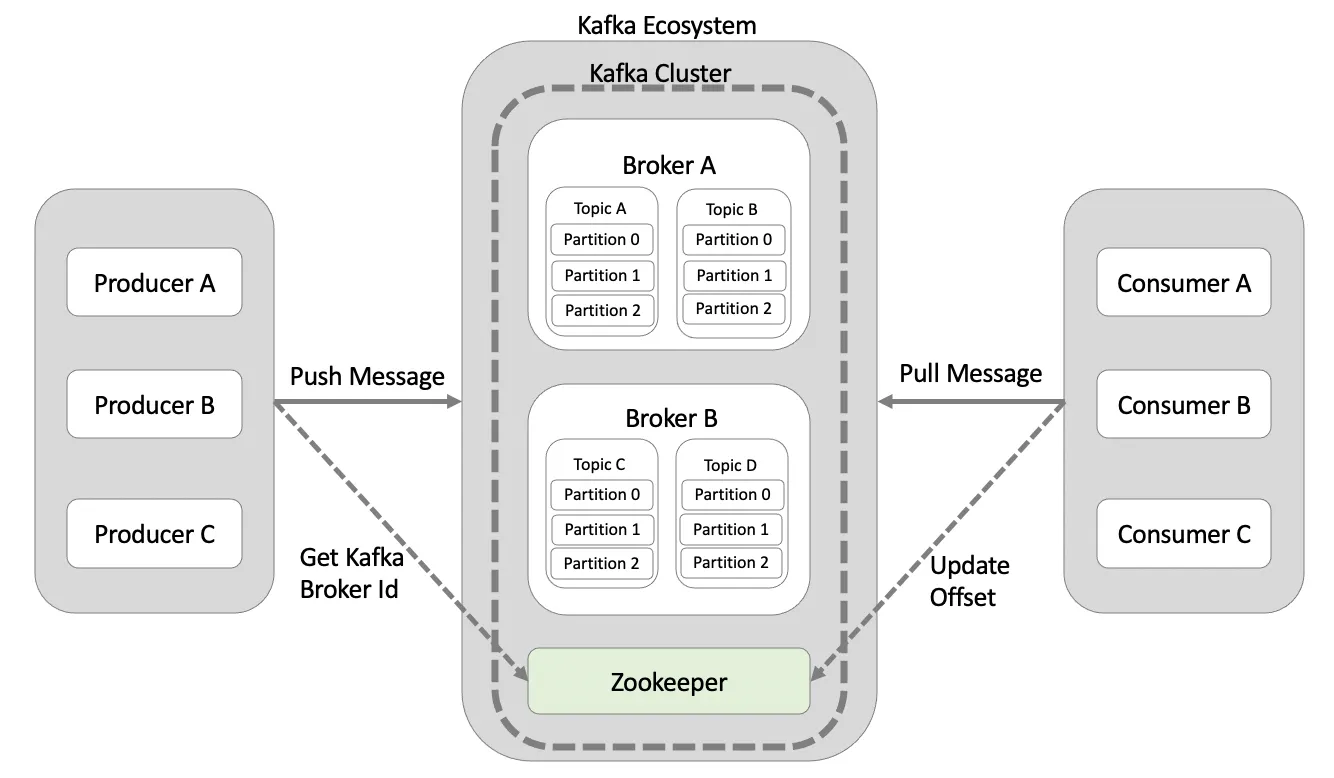
- Kafka의 주요한 Components
- Brokers: The dedicated servers to receive, store, process, and distribute events
- Topics: The containers or databases of events
- Partitions: Divide topics into different brokers
- Replications: Duplicate partitions into different brokers
- Producers: Kafka client applications to publish events into topics
- Consumers: Kafka client applications are subscribed to topics and read events from them
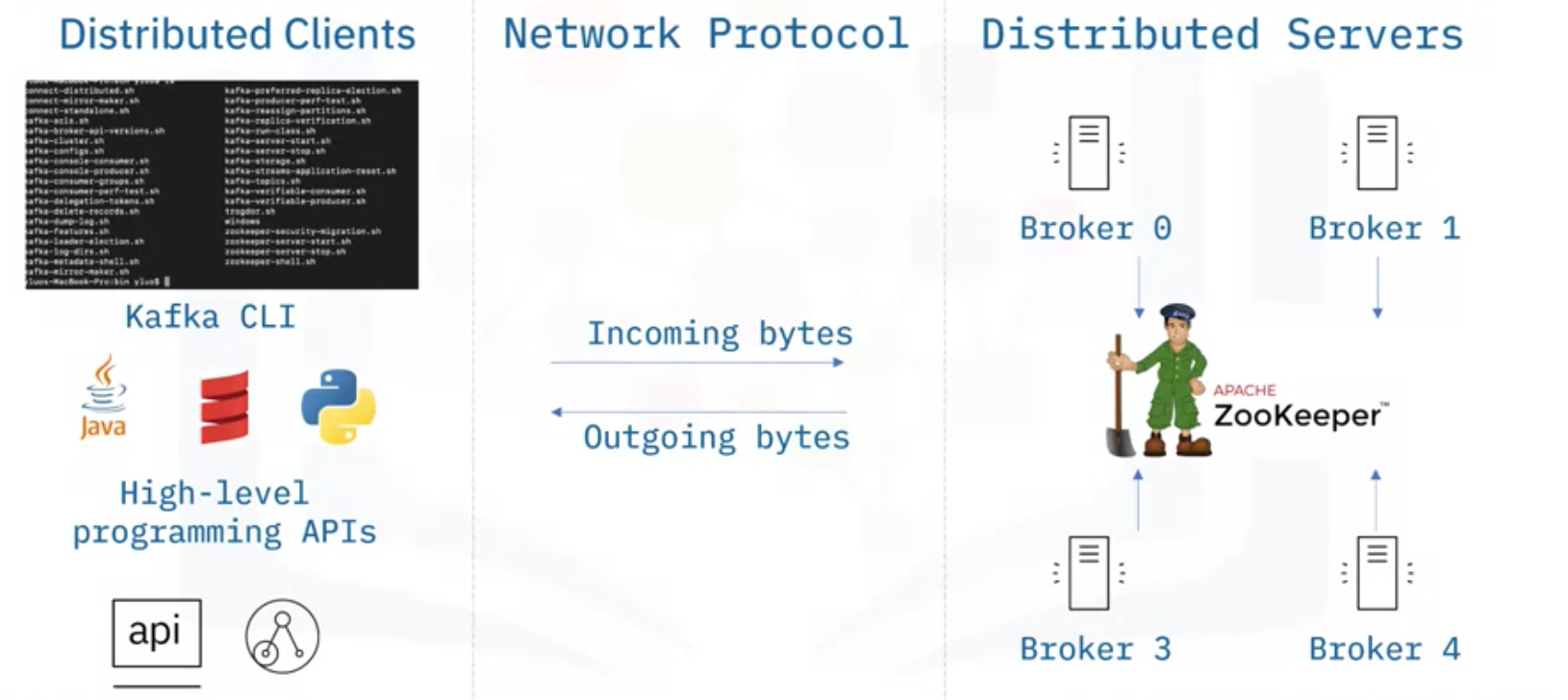
- Kafka는 Distributed Client-server Architecture의 형태
- Sever 사이드에서는
Broker라고 불리는 클러스터가 있고, 이벤트를 수신, 저장, 배포하는 역할 수행 - 이러한 Broker들은 효율적으로 작업되도록
ZooKeeper라고 불리는 분산 시스템으로부터 관리됨 - Kafka는 TCP 기반의 네트워크 통신 프로토콜을 사용해 클라이언트와 서버 사이에서 데이터를 교환
- Client 사이드에서는 서버와 통신하기 위해 Kafka CLI나 자바나 파이썬 같은 클라이언트를 제공
- Sever 사이드에서는
- Kafka의 주요한 특징
- 많은 양의 데이터 처리가 가능하고, 동시에 처리할 수 있는 확장성이 뛰어난 Distribution System
- Kafka 클러스터는 이벤트 스트리밍을 병렬로 처리할 수 있는 Event Brokers가 존재 (빠르고, 확장성 좋음)
- 이벤트 저장 공간을 여러 개의 파티션으로 나누거나, 복제하여 장애를 방지하고 안정성이 높음
- 이벤트를 영구적으로 저장할 수 있음
- 오픈소스이기 때문에 무료로 사용할 수 있고, 커스터마이징이 가능
- 오픈소스이고, 문서화도 잘 되어 있긴 하지만 Kafka 클러스터를 구축하기 위해서는 인프라 설계가 필요 (어려움)
- 이를 위해서 Confluent Cloud, IBM Event Streams, Amazon MSK 같은 서비스들도 존재
4. Kafka를 통해 Event Streaming 파이프라인 만들기
- Kafka 클러스터는 하나 이상의 Broker를 포함하고 있고, 이를 이벤트 수신, 저장, 처리, 배포 전용 서버로 이해 가능
- Broker는 ZooKeeper라는 전용 서버에 의해 동기화 되고, 관리됨
- Broker는 Event를 Topic으로 저장 및 관리하고, Consumers에게 배포
- Kafka는 다른 분산 시스템과 마찬가지로, 분할 (Partitioning) 및 복제 (Replicating) 개념을 구현
- 이를 통해 데이터 처리량을 향상시켜서 여러 Broker와 동시에 병렬적으로 작업이 가능
- 일부 Broker가 다운 되더라도, 여전히 다른 Broker에서 복제하여 작업을 수행할 수 있음
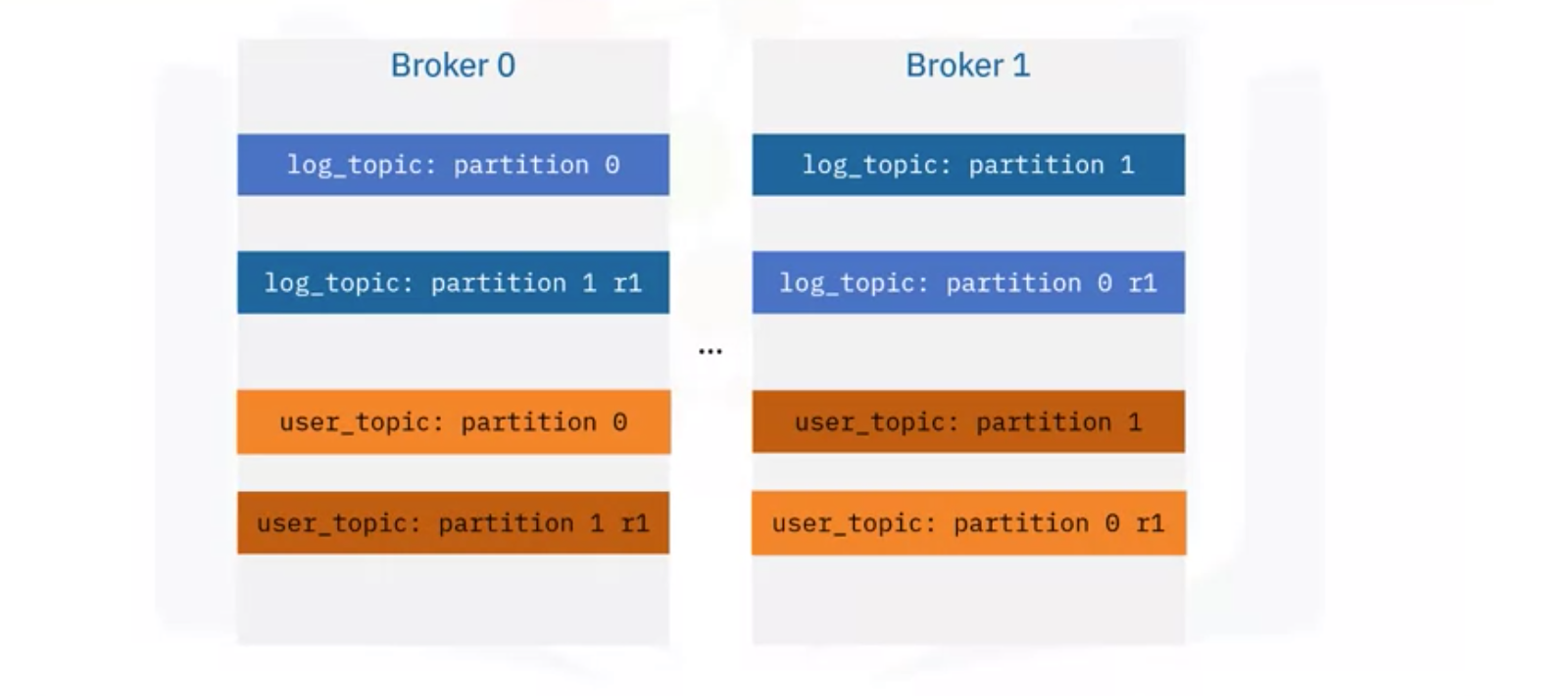
- 즉, 아래 그림과 같이 log topic과 user topic이 두 파티션으로 구분되고, 복제되어 서로 다른 Broker에 저장
- Kafka CLI는 사용자가 이벤트 스트리밍 파이프라인을 구축할 수 있도록 도와줄 수 있음
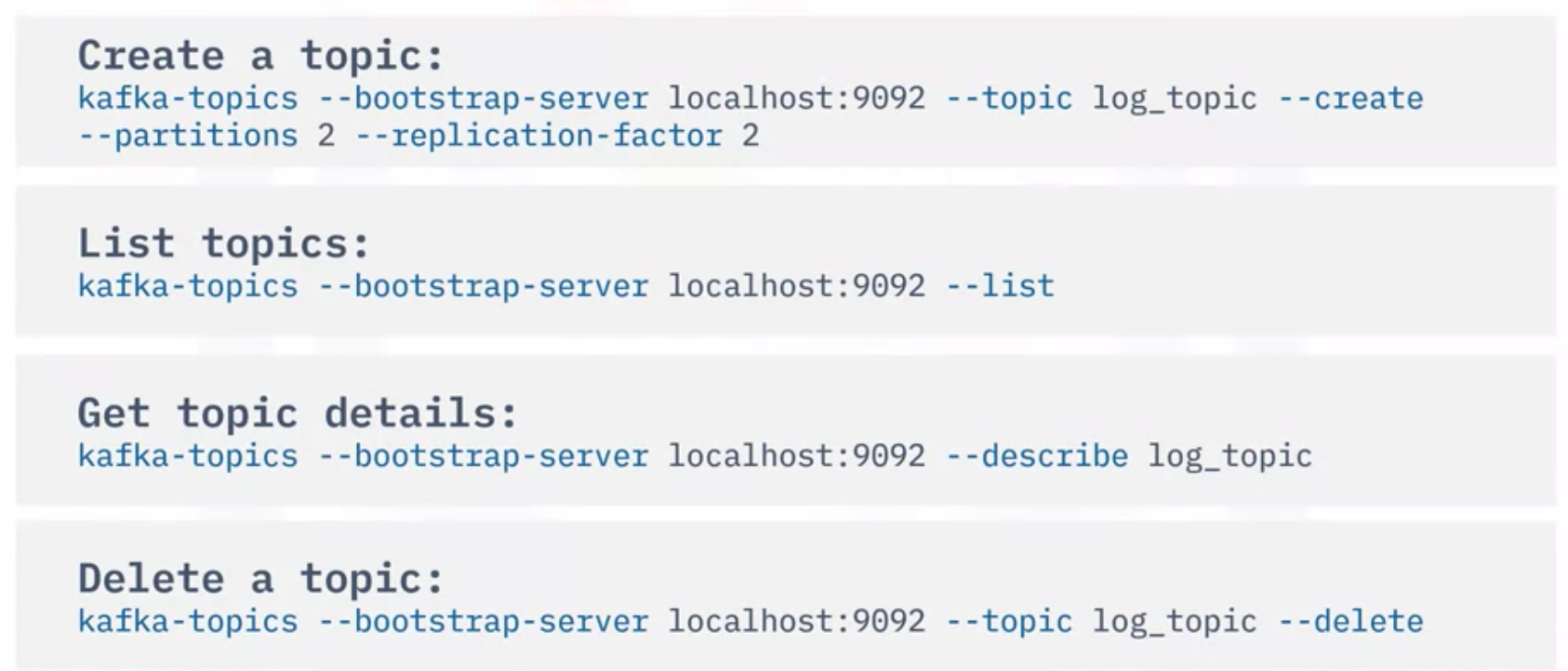
- Kafka-topics 스크립트는 간단하게 Kafka 클러스터의 항목을 관리하는데 자주 사용할 수 있는 스크립트
- Create a topic, List topics, Get topics details, Delete a topics
- Kafka Producer는 등록된 순서에 따라 Topic 파티션에 이벤트를 등록하는 클라이언트 응용 프로그램
- Producer에서 Event를 게시할 때, 선택적으로 Event를 Key와 연결할 수 있음
- 동일한 Key에 연결된 Event는 동일한 Topic 파티션에 Publish 됨
- Key와 연결되지 않은 Event는 로테이션으로 Topic 파티션에 Publish 됨
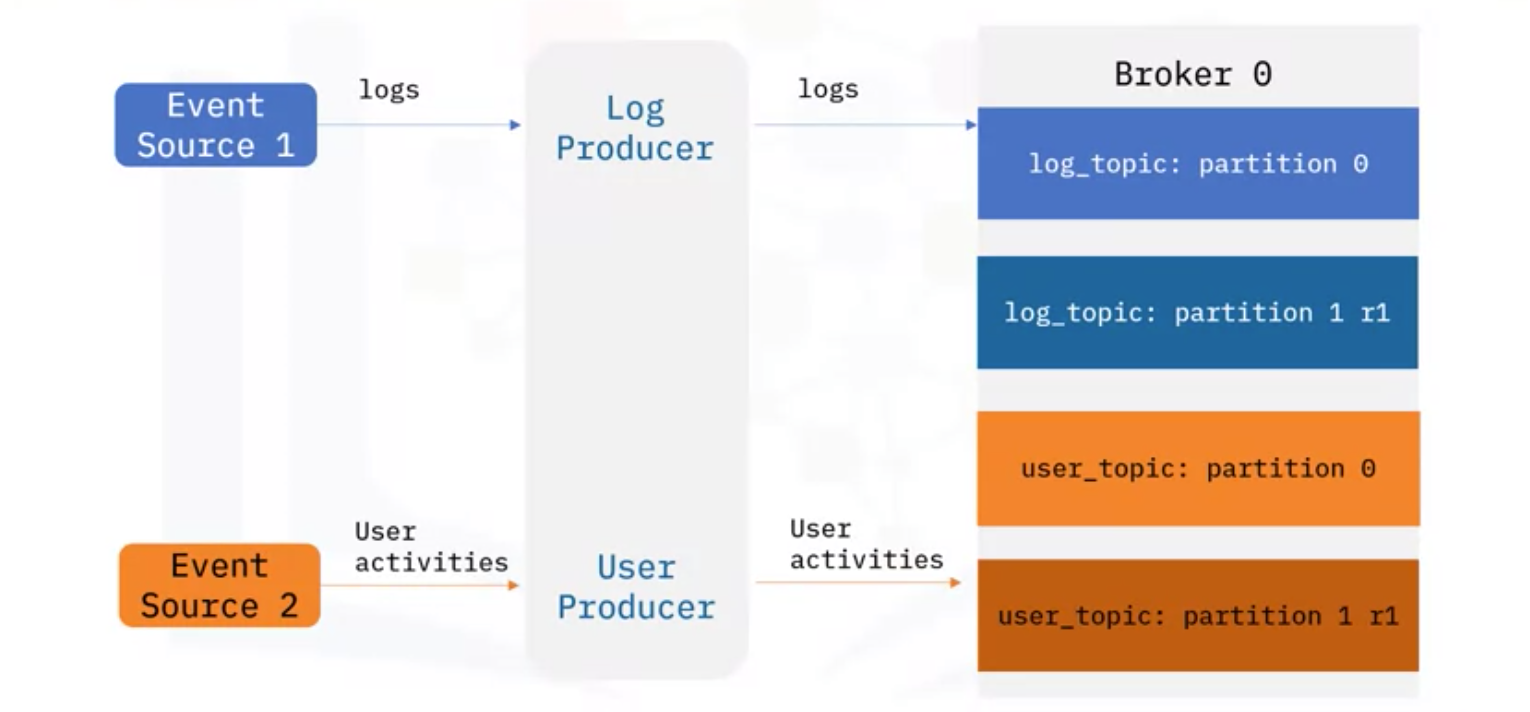
- 아래 그림에서 같이 Log를 만드는 Event Source 1과 사용자 활동을 추적하는 Event Source 2가 있다고 가정
- Kafka Producer를 통해 log topics과 user topics을 각각의 파티션에 publish
- 이때, 프로그램의 이름이나 사용자 ID 같은 Key 값으로 이벤트를 연결할 수도 있음
- Producer는 Topic에 대하여 Event를 Publish 하거나, Write 하는 것이 가장 중요
- 아래 그림에서처럼 Key 값을 포함하거나, 포함하지 않고
Producer를 시작시킬 수 있음- Key를 주는 경우에는, 사용자 1에 대한 모든 Event가 동일한 파티션에 저장되어 Consumer가 사용할 것

- Event가 Publish 되고, Topic 파티션에 저장되면, Event를 읽을 수 있는
Consumer를 만들 수 있음 - Consumer는 저장된 Event를 읽고, Topic을 다룰 수 있는 클라이언트 어플리케이션
- Consumer는 Topic 파티션의 데이터를 publish 된 순서에 따라서 읽음
- 각각의 파티션에 Offset (상대 위치)를 저장하고, 이를 이용하여 Event가 발생할 때, 그것을 읽을 수 있음
- Offset을 0으로 재설정할 수 있고, 이를 통해 Consumer는 Topic 파티션의 모든 이벤트를 처음부터 읽을 수 있음
- Kafka에서 Producer와 Consumer는 완전히 분리되어 있어서 (Fully Decoupled) Producers는 Consumers와 동기화 시킬 필요가 없고, Event가 Topic에 저장된 후에는 Consumer가 독립적으로 스케줄에 따라 작업
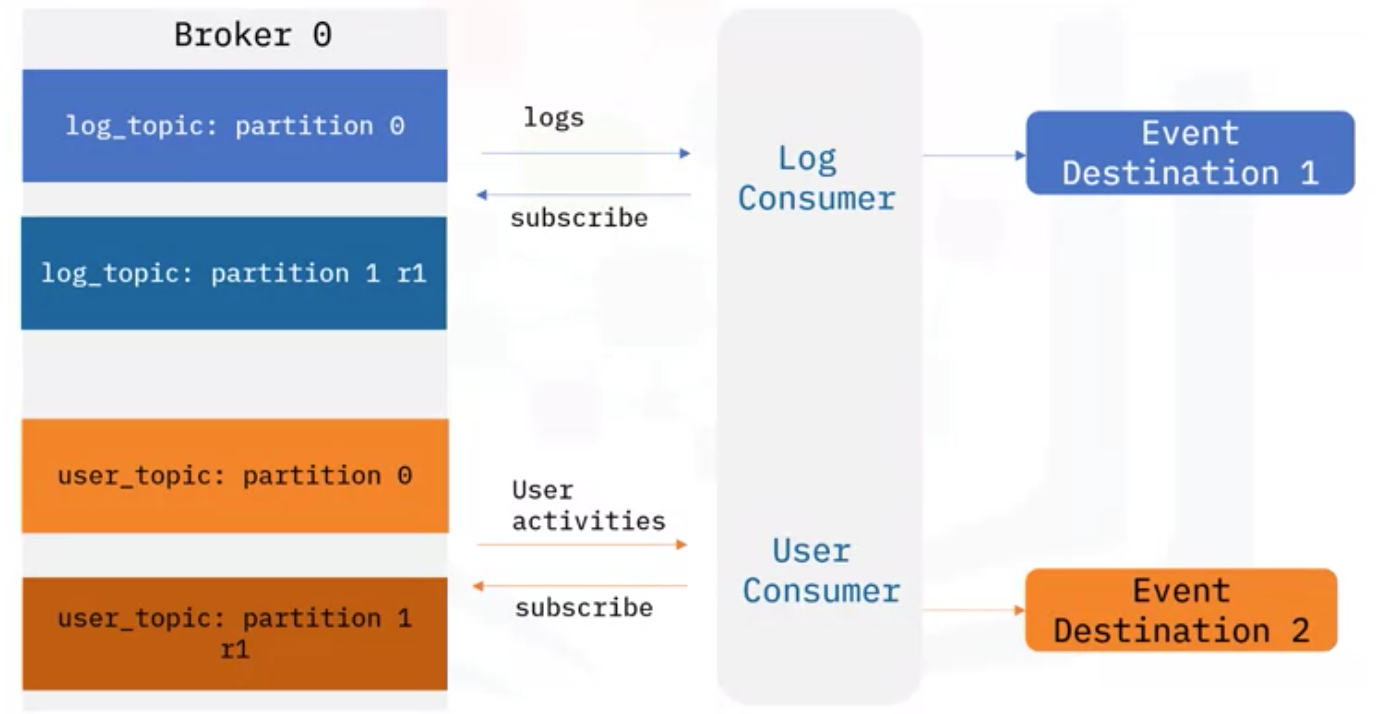
- 로그와 사용자 행동 이벤트를 Topic 파티션으로부터 publish 하기 위해서는 거기에 맞는 각각의 Consumer가 필요함
- 그리고 Kafka는 Consumer에게 Event를 push하고, Consumer는 Event Destination으로 보냄
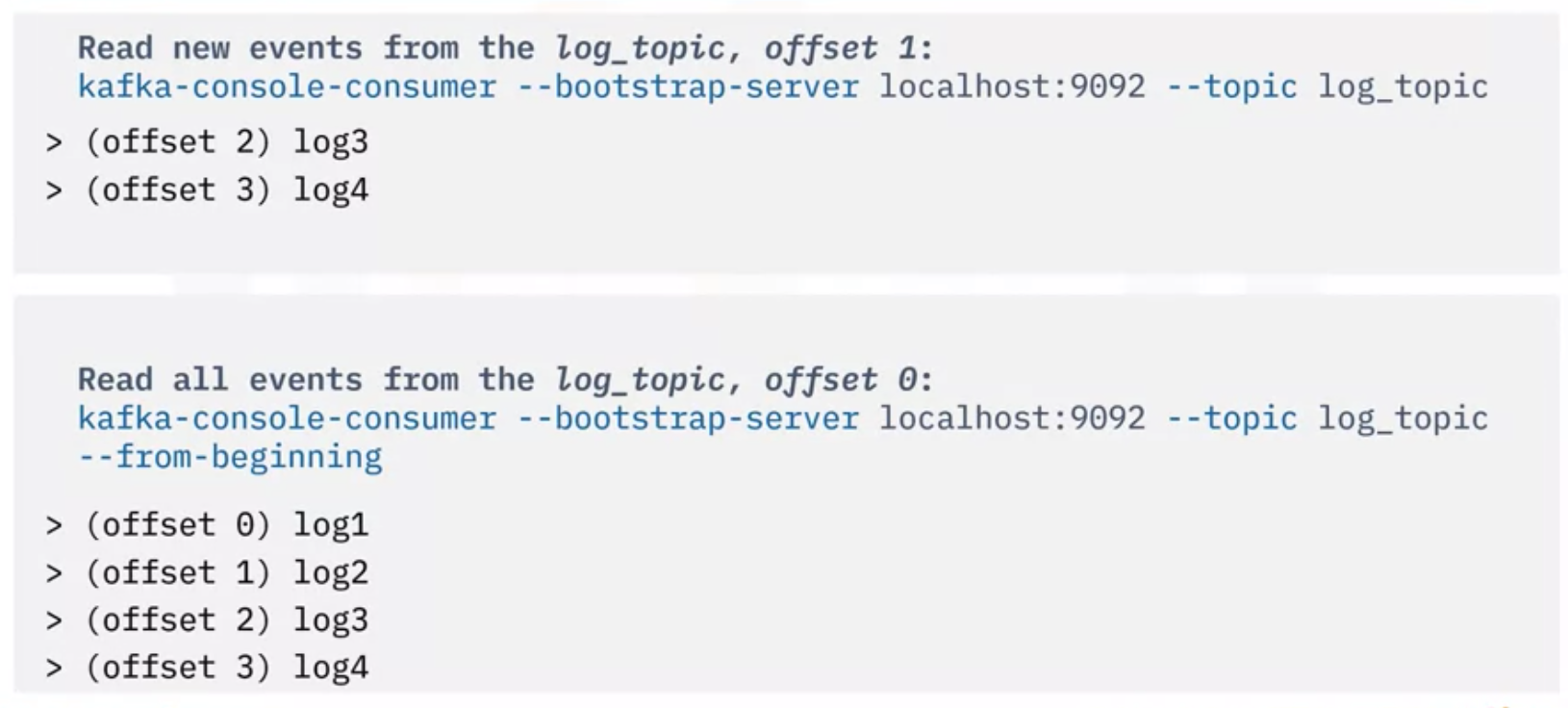
- Kafka Consumer Script를 통해 Consumer를 실행시키기 위해서는 다음과 같이 수행
- log topic으로부터 Event를 읽은 후, Script를 실행하여 Kafka 클러스터와 Topic을 지정
- Consumer는 마지막 파티션 Offset에서부터 시작해서 새로운 이벤트만 읽음
- 새로운 이벤트를 처리한 후에는 파티션 Offset도 업데이트 되고, Kafka에 반영
- 가끔씩 사용자가 처음부터 모든 Event를 읽고자 한다면, 옵션을 추가해주면 됨
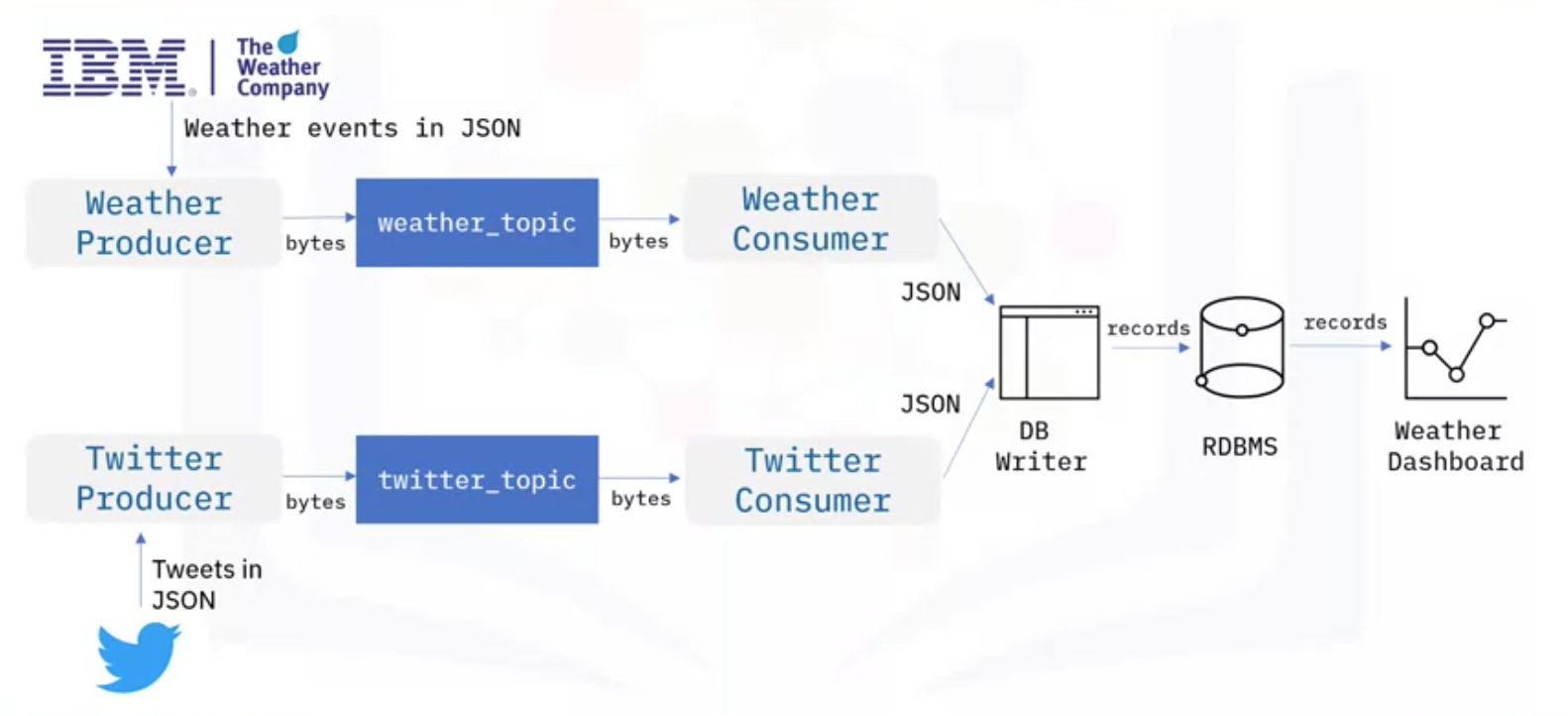
5. Weather Pipeline Example
- 날씨와 트위터의 Event Stream을 수집하고, 사람들이 트위터에서 극단적 날씨에 대해 말하는 것을 분석하고자 함
- 이를 위해 JSON 포멧으로 날씨와 트위터 데이터를 실시간으로 받는 IBM Weather API, Twitter API 사용
- 날씨와 트위터를 JSON 형태로 Kafka에서 받기 위해서는, Kafka 클러스터에서 weather topic과 twitter topic 필요
- Weather Producer와 Twitter Producer를 만들고, 데이터는 바이트로 직렬화 되어 Kafka Topic에 저장
- 2개의 Topic에서 Event를 읽기 위해서 Producer와 마찬가지로, Weather Consumer와 Twitter Consumer 필요
- Kafka Topic에 저장된 바이트 (Bytes)는 Event JSON 데이터로 역직렬화 (Deserialized)
- 데이터들을 관계형 데이터베이스로 전송하기 위해 DB Writer를 사용해서 JSON 파일 분석 및 DB 레코드를 만듦
- 그 후, SQL 쿼리를 통해서 이 레코드들을 데이터베이스에 작성하고, 저장
- 마지막으로는 앞서 만든 DB로부터 데이터를 활용해 대시보드를 만들고 시각화 및 분석을 진행할 수 있음
6. Kafka Streaming Process
- Event Streaming에서 데이터 엔지니어는 데이터 전송, 필터링, 집계, 향상 등을 통해 데이터를 처리해야 함
- Streams 처리를 위해 개발된 어플리케이션을 Stream Processing Applications이라고 함
- Kafka 기반 Stream Processing Applications 구현을 위한 간단한 방법은 한 Topic에서 Event를 읽고, 처리한 후에 다른 Topic을 Publish 하기 위해 Ad hoc 데이터 프로세서를 구현하는 것
- Weather API로 JSON 데이터를 받은 후, Weather Producer는 Weather Topic으로 Publish
- Consumer는 Weather Topic으로부터 데이터를 읽음
- Ad hoc 데이터 프로세서를 만들어서 극단적으로 높은 기온과 같이 이상기후 데이터만 필터링하도록 함
- 프로세서는 간단한 스크립트 파일이거나, Kafka에서 클라이언트와 함께 작동해 데이터를 다루는 프로그램
- 프로세서는 처리된 데이터를 다른 Produer로 전달하고, Publish 하여 Topic을 만듦
- 그 Topic은 Consumer로 전달 및 처리되고, 시각화를 위해 대시보드 등에 전달
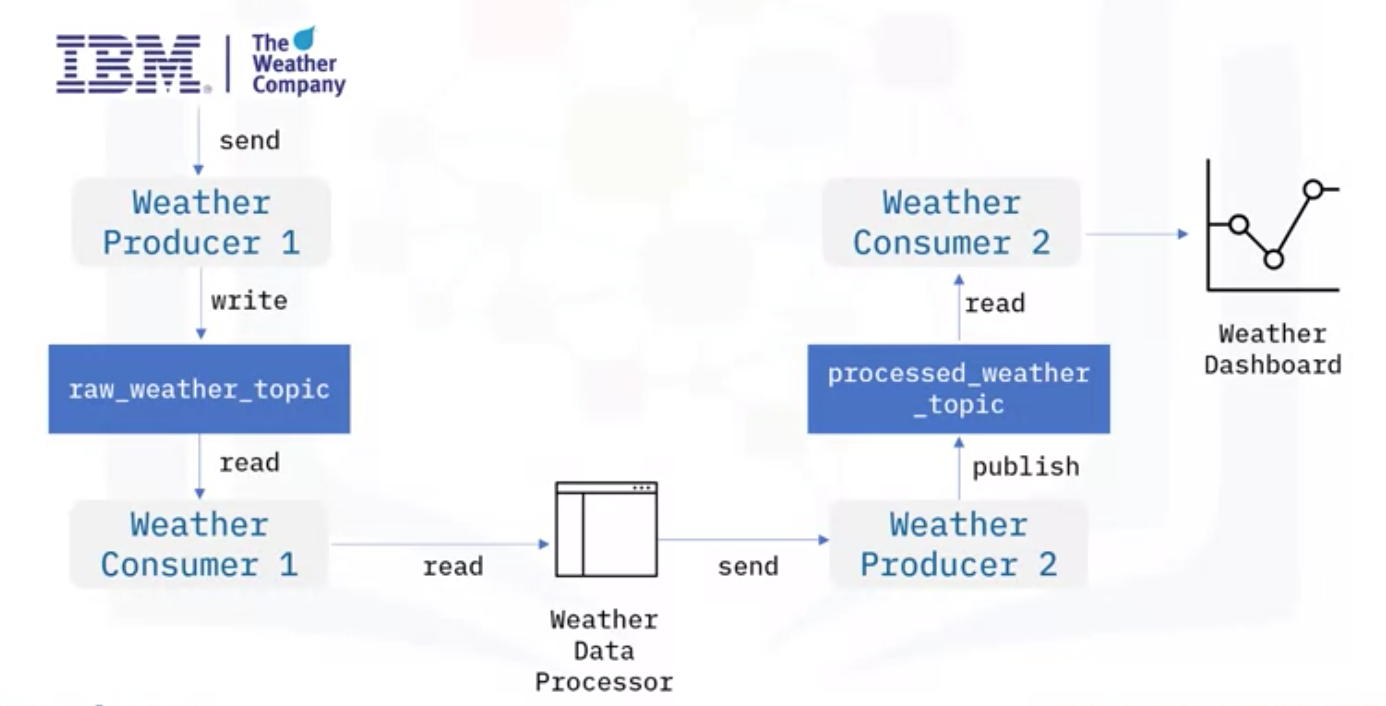
- Ad hoc 프로세서는 처리해야 할 많은 Topic이 있는 경우에 복잡해질 수 있는데, Kafka는 이를 해결할 수 있음
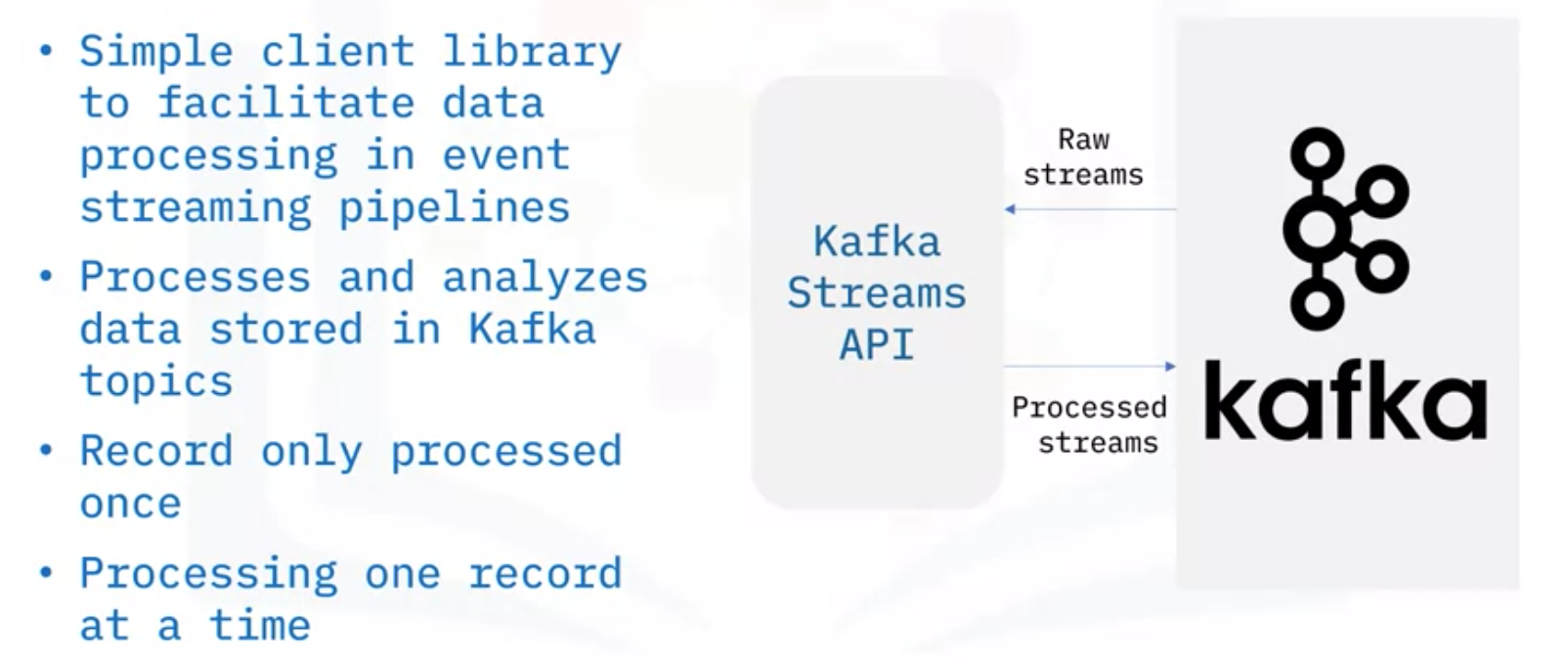
- Kafka는 Stream Processing을 위해서 Streams API를 제공
- Kafka Streams API는 이벤트 스트리밍 파이프라인에서 데이터 처리를 돕는 간단한 클라이언트 라이브러리
- Kafka Topics에 저장된 데이터를 처리하고 분석하기 때문에 Streams API의 입출력이 모두 Kafka Topics
- Kafka Streams API는 각각의 기록들이 한 번만 처리되도록 보장
- Kafka Streams API는 한 번에 하나의 레코드만 처리
- Kafka Streams API는 Stream-processing topology 라는 계산 그래프를 기반으로 함
- 이 Topology에서 각 노드는 Upstream 프로세서에서 Streams을 받고, 맵핑, 필터링, 포메팅 등과 같은 데이터 변환을 수행하며, 다운스트림 프로세서로 출력 Stream을 생성하는 Stream 프로세서
- 그렇기 때문에 그래프의 가장자리는 Input, Output Streams
- 프로세서에는 다음과 같은 두 가지 특별한 유형이 있음
- Source 프로세서: Consumer처럼 Kafka Topic을 처리하고, 처리된 Streams을 Downstream 프로세서로 전달
- Sink 프로세서: Producer처럼 받은 Streams을 Kafka Topic으로 Publish 하는 역할
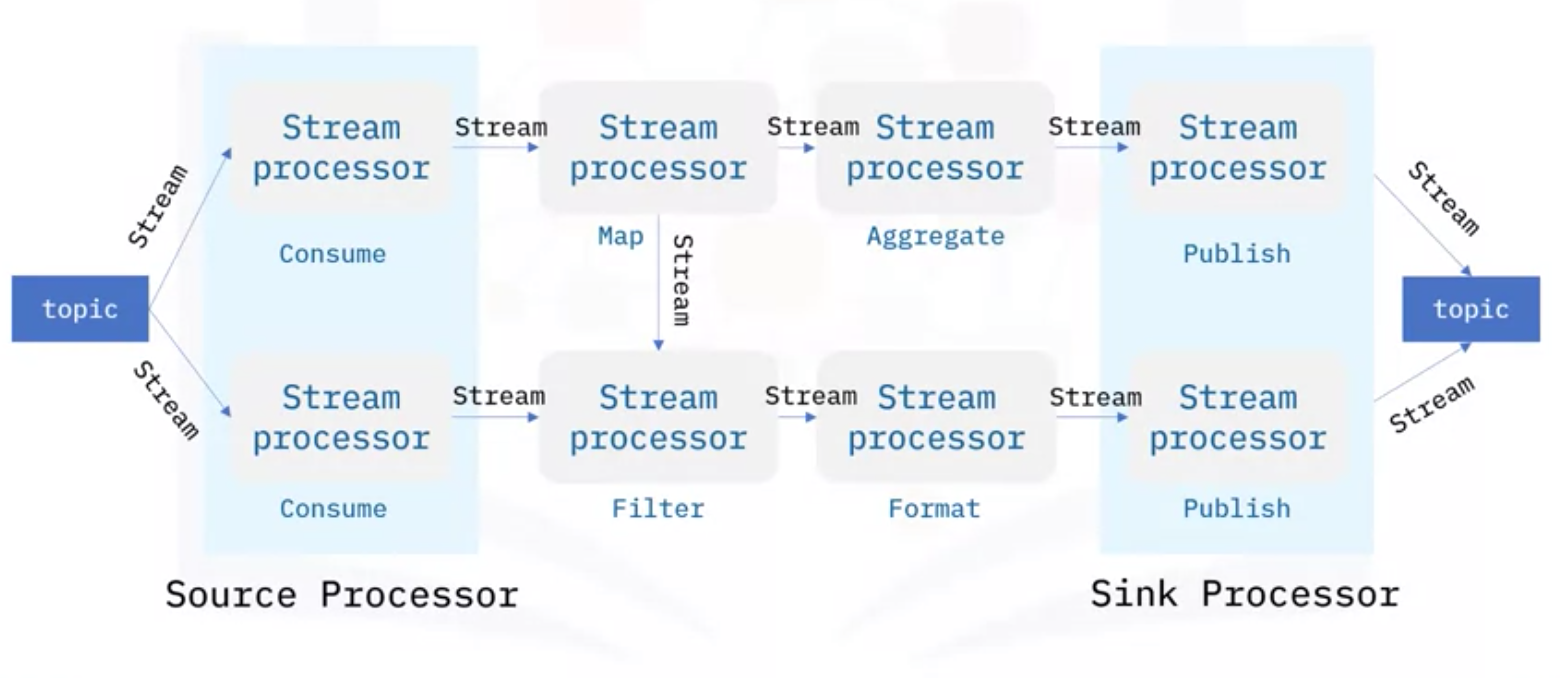
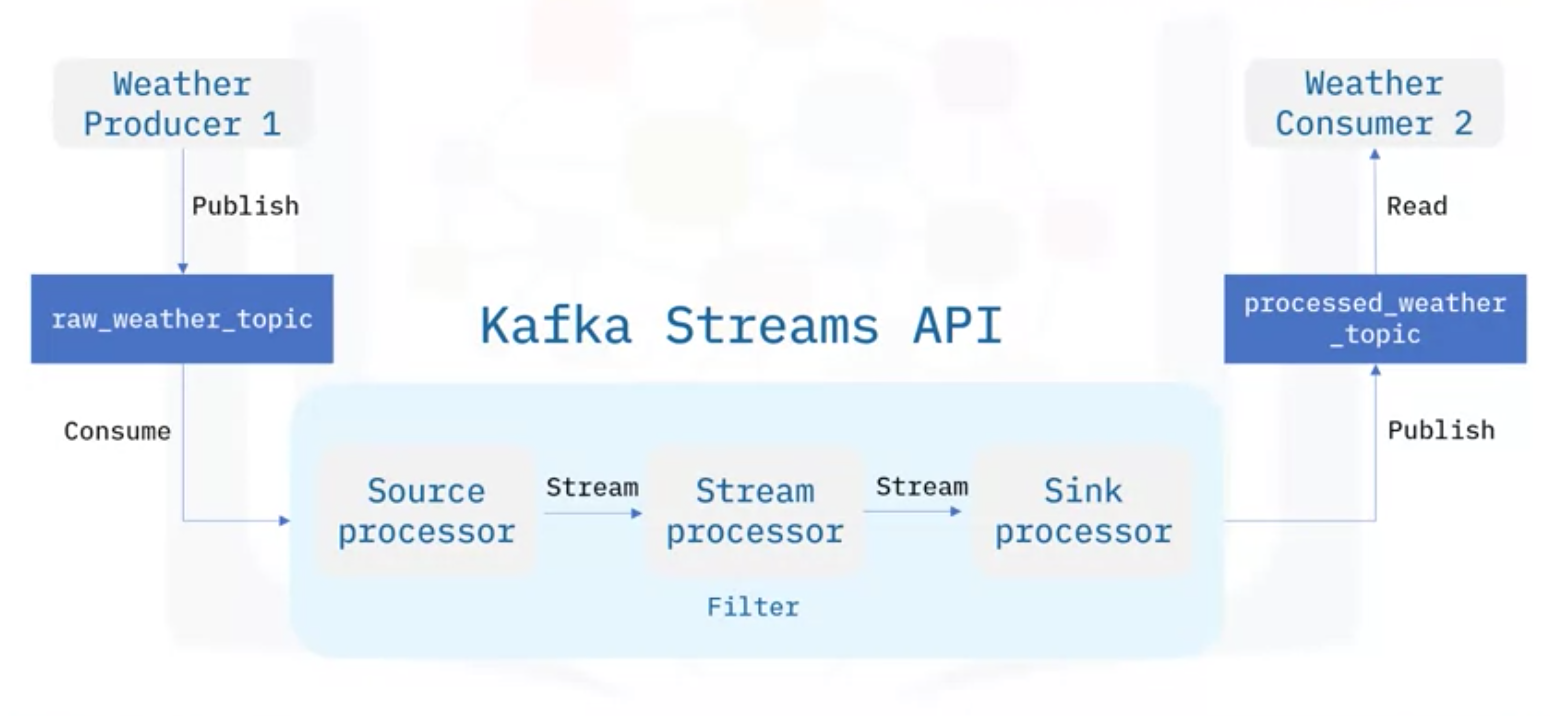
- Kafka Streams API를 통해 날씨 스트림 처리 어플리케이션을 다시 설계한다면 다음과 같음
- Ad hoc 프로세서를 개발하는 것 대신, Kafka Streams API를 사용하면 됨
- Kafka Streams Topology에는 세 개의 Stream 프로세서가 있음
- Source 프로세서: Raw Weather Topic으로부터 Weather Streams을 처리하고, Stream 프로세서로 전달
- Stream 프로세서: 이상기후와 같은 조건을 필터링하고, Sink 프로세서로 전달
- Sink 프로세서: 처리된 Weather Topic의 결과를 Publish
- 이러한 방식은 처리해야 할 Topic의 수가 많은 경우에 Ad hoc 데이터 프로세서보다 훨씬 더 쉬운 방법