
 |
간단한 책 소개
이 책은 데이터베이스를 다룰 수 있는 SQL의 개념과 사용 방법을 소개하고 있습니다.
대표적인 DBMS인 오라클, SQL Server, MySQL, PostgreSQL 등을 비교하면서 보여줍니다.
회사를 다녀보니, 데이터를 다루는 과정에서는 파이썬보다 SQL과 DB에 대한 이해가 더 필요하다는 것을 느꼈습니다.
따라서 데이터베이스를 다룰 수 있는 (거의 유일한) SQL을 학습하며, DB에 대한 이해도를 높이려고 합니다.
이 책에서는 다양한 DBMS를 소개하고 있지만, 실제로 가장 많이 사용되고 있고 제 필요에 따라서,
DB의 기초 내용과 MySQL, PostgreSQL 등의 내용을 중점적으로 살펴 볼 예정입니다.
| Chapter | Title | Main Topics |
|---|---|---|
| 1강 | 데이터 모델 설계 | 기본키, 외래키, 중복 데이터 제거, 정규화, 역정규화 |
| 2강 | 인덱스 설계와 프로그램적 처리 | 인덱스, 트리거, 선언적 제약 조건 |
| 3강 | 데이터 모델 설계를 변경할 수 없는 경우 | 뷰, ETL, 요약 테이블, UNION |
| 4강 | 데이터 필터링과 검색 | 관계 대수, CASE, 다중 조건 문제, 데이터 분할, 사거블 쿼리 |
| 5강 | 집계 | GROUP BY, HAVING, DISTINCT, 윈도우 함수, 이동 집계 |
| 6강 | 서브쿼리 | 서브쿼리, CTE, 조인 |
| 7강 | 메타데이터 획득, 분석 | 메타데이터 수집 방법, 실행 계획의 작동 원리 |
| 8강 | 카티전 곱 | 로우 조합 |
| 9강 | 탤리 테이블 | 윈도우 함수, 날짜 테이블, 피벗 |
| 10강 | 계층형 데이터 모델링 | 인접 리스트 모델, 중첩 집합 |
| Appendix | - | 데이터 타입, 산술 연산, 함수 |
Chapter 1. 데이터 모델 설계
Better way 1 - 모든 테이블에 기본키가 있는지 확인하자
- 관계형 모델을 따르기 위해서는 한 테이블에 있는 특정 row와 다른 row를 구별할 수 있어야 함
- 테이블에 기본키가 없으면, 일관성 없는 데이터가 쌓여 쿼리 속도가 느리고, 정확한 정보 조회가 불가능 할 수도 있음
- So, 모든 테이블에는 column 한 개 이상으로 구성된
기본키 (Primary Key)가 필요- 기본키는 row마다 유일해야 함
- 기본키는 null 값을 가질 수 없음
- 기본키는 안정적인 값이어야 함 (값을 갱신할 필요가 없음)
- 기본키는 가능한 간단한 형태이어야 함
- 기본키 설정을 하기 위한 가장 일반적인 방법은 의미 없는 숫자 데이터로 자동 생성되는 컬럼을 기본키로 만드는 것
- RDBMS에 따라 이름이 구분되는데, DB2, SQL Server, 오라클 12c에서는
IDENTITY - 액세스에서는
AutoNumber, MySQL,에서는AUTO_INCREMENT, PostgreSQL에서는serial컬럼
- RDBMS에 따라 이름이 구분되는데, DB2, SQL Server, 오라클 12c에서는
- RDBMS에서 참조 무결성 (Reference Integrity, RI)이라는 개념은 매우 중요
- RI를 준수한다는 것은 null이 아닌 외래키 (Foreign Key)가 설정된 자식 테이블의 각 레코드와 일치하는 레코드가 부모 테이블에 존재한다는 것
- ex) Orders 테이블에서 고객 정보 컬럼에 외래키를 설정하여 Customers 테이블의 기본키와 연결된 것
- 이렇게 되면, 같은 이름을 가진 고객이 있어도 Customers 테이블의 각 로우는 유일하기 때문에 고객 식별 가능
- 복합 기본키 (Compound Primary Key)는 다음의 이유로 효율성이 떨어지므로 지양하기
- 기본키를 정의 할 때, 해당 컬럼에 유일한 인덱스를 만드는데, 컬럼 두 개 이상에 인덱스를 만드는게 비효율적
- 기본키로 조인을 수행하는데, 기본키가 여러 컬럼으로 구성되면 쿼리가 복잡하고 느려짐
Better way 2 - 중복으로 저장된 데이터 항목을 제거하자
- 데이터가 중복으로 저장된다면?
- 일관되지 않은 데이터 이슈
- 비정상적인 삽입, 갱신, 삭제 처리 이슈
- 디스크 공간 낭비 이슈
- 정규화 (Normalization)
- 중복 데이터를 저장하면서 발생하는 문제를 없애려고 정보를 주제 (subject) 별로 분할하는 프로세스
- 여기서 ‘중복’이라는 것은 사용자가 동일한 데이터를 한 군데 이상에서 입력하는 것을 뜻함
- 정규화의 목표는 한 DB에서 동일한 테이블이든, 다른 테이블이든 반복되는 데이터를 최소화하는 것
- 외래키 제약 조건: 복수의 테이블 사이에 관계를 선언함으로써 데이터의 무결성을 보장해 주는 역할

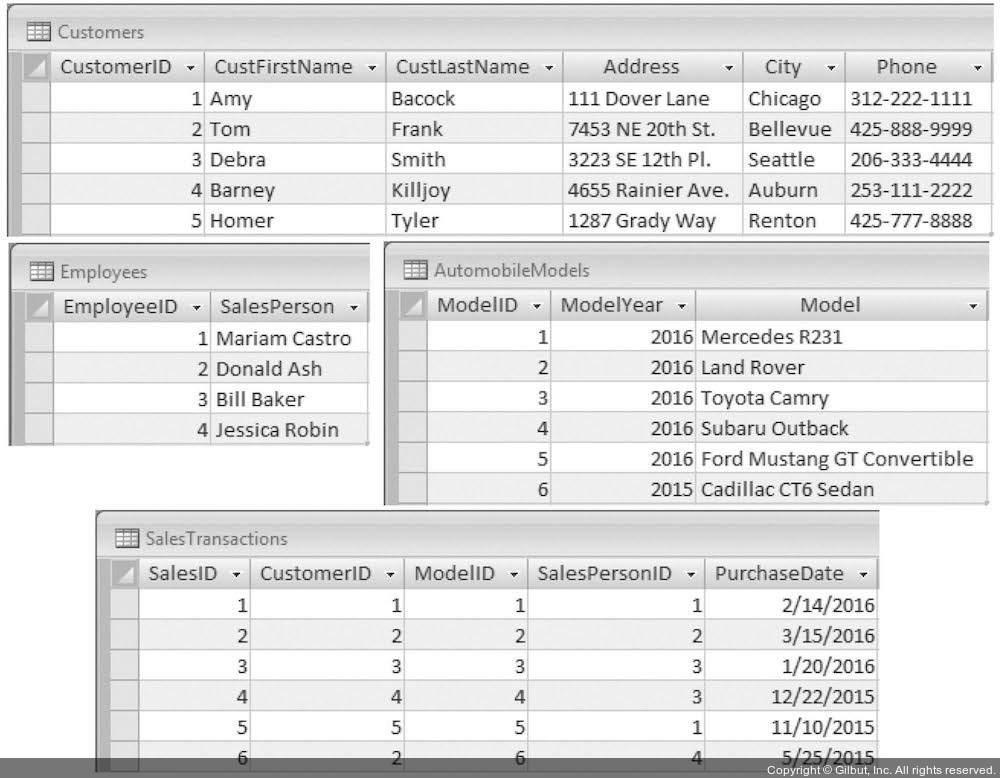
위 1-3 그림에서 볼 수 있는 것처럼 기존에는 정규화 되어 있지 않고, CustomerSales 라는 하나의 테이블로 고객 정보와 종업원 정보, 구매 정보 등이 관리되고 있었음. 이 경우에는 고객이 물건을 구매하는 경우에 PurchaseDate에 관련된 정보만 추가되는 것이 아니라, 다른 모든 컬럼들도 영향을 받고 있음. 게다가 고객 정보가 똑같은데, 데이터가 다르게 들어오는 경우에는 처리하는게 복잡하게 될 수 있음.
따라서 1-4 그림처럼 주제 (subject) 별로 분할하는 정규화 과정을 수행하여, Customers, Employees, AutomobileModels, SalesTransactions 테이블로 나눠서 관리할 수 있음. 그러면서 기본키와 외래키를 통해 데이터의 중복을 제거하고, 효율적으로 관리할 수 있음. 또한 아래 쿼리를 통해 데이터를 다시 1-3 그림처럼 복구할 수도 있음.
1
2
3
4
5
6
7
8
9
SELECT st.SalesID, c.CustFirstName, c.CustLastName, c.Address,
c.City, c.Phone, st.PurchaseDate, m.ModelYear, m.Model, e.SalesPerson
FROM SalesTransactions st
INNER JOIN Customers c
ON c.CustomerID = st.CustomerID
INNER JOIN Employees e
ON e.EmployeeID = st.SalesPersonID
INNER JOIN AutomobileModels m
ON m.ModelID = st.ModelID;
Better way 3 - 반복 그룹을 제거하자
영향도 (비용) 측면에서 컬럼은 비싸고, 로우는 싸다.- DB 정규화의 목표는 데이터의 반복 그룹을 제거하고, 스키마 변경을 최소화 하는 것
- 데이터의 반복 그룹을 제거하면, 인덱싱을 사용하여 데이터 중복을 방지하고, 쿼리도 간소화 할 수 있음
UNION, UNION ALL쿼리를 활용
Better way 4 - 컬럼당 하나의 특성만 저장하자
- 관계형 용어에서 관계 (테이블)는 오직 한 주제나 액션만 기술해야 함
- 단일 컬럼에 특성 값을 두 개 이상 저장하는 것은 올바르지 못함
- 검색을 하거나, 값을 집계할 때 특성 값을 분리하기 어렵기 때문
- 중요한 개별 특성은 자체 컬럼에 넣는 것을 고려해야 함
| Auth ID | Auth Name | Auth Address |
|---|---|---|
| 1 | John L. Viescas | 144 Boulevard Saint-Germain, 75006, Paris, France |
| 2 | Douglas J. Steele | 555 Sherbourne St., Toronto, ON M4X 1W6, Canada |
| 3 | Ben Clothier | 2015 Monterey St., San Antonio, TX 78207, USA |
| 4 | Tom Wickerath | 2317 185th Place NE, Redmond, WA 98052, USA |
- 위 테이블에는 다음과 같은 문제점 존재
- 불가능하지는 않지만, ‘성’을 찾기 힘듦
- 이름을 검색할 때, 효율성이 떨어지는
LIKE, substring 연산자를 사용해 이름을 추출해야 함 - 거리 이름, 도시, 주, 우편번호를 쉽게 찾을 수 없음
- 데이터를 그룹으로 묶으면, 그룹화 된 데이터에서 우편번호, 주, 국가를 추출하기 힘듦
| Auth ID | Auth First | Auth Mid | Auth Last | Auth St Num | Auth Street | Auth City | Auth St Prov | Auth Postal | Auth Country |
|---|---|---|---|---|---|---|---|---|---|
| 1 | John | L. | Viescas | 144 | Boulevard Saint-Germain | Paris | - | 75006 | France |
| 2 | Douglas | J. | Steele | 555 | Sherbourne St. | Toronto | ON | M4X 1W6 | Canada |
| 3 | Ben | - | Clothier | 2015 | Monterey St. | San Antonio | TX | 78207 | USA |
| 4 | Tom | - | Wickerath | 2317 | 185th Place NE | Redmond | WA | 98052 | USA |
- 이렇게 테이블을 수정하면 컬럼당 특성이 한 개만 있음
- 따라서 하나 이상의 개별 특성에서 검색이나 그룹핑을 쉽게 할 수 있음
- 또한 아래 SQL 쿼리를 통해서 원래 데이터를 생성할 수도 있음
1
2
3
4
5
6
7
8
9
10
11
SELECT AuthorID AS AuthID, CONCAT(AuthFirst,
CASE
WHEN AuthMid IS NULL
THEN ' '
ELSE CONCAT(' ', AuthMid, ' ')
END, AuthLast) AS AuthName,
CONCAT(AuthStNum, ' ', AuthStreet, ' ',
AuthCity, ', ', AuthStProv, ' ',
AuthPostal, ', ', AuthCountry)
AS AuthAddress
FROM Authors;
- 올바른 테이블 설계는 개별 특성을 자체 컬럼에 할당함. 한 컬럼에 여러 특성이 포함되지 않도록 해야 함
- 일부 app에서는 주소나 전화번호 같은 컬럼의 일부를 걸러내기 위해 최소 수준의 데이터 조각으로 분할해야 함
- 보고서나 목록을 뽑으려고 특성들을 재결합 할때는 SQL의 문자열 연결 기능을 사용함
Better way 5 - 왜 계산 데이터를 저장하면 좋지 않은지 이해하자
- 계산 컬럼을 현행화 하는 가장 원시적인 방법은 계산에 사용되는 원천 컬럼이 있는 테이블에 트리거를 추가하는 것
- 트리거는 대상 테이블에 데이터가 입력, 갱신, 삭제 될 때 수행하는 코드
- 하지만 트리거는 정확하게 작성하기 어렵고, 비용도 비싸다는 단점이 있음
- 트리거보다 나은 선택은 테이블을 생성할 때 계산 컬럼을 정의하는 방법이 있음 (몇몇 DB 시스템에서 제공)
- 이렇게 하면 트리거를 작성할 때 필요한 복잡한 코드를 작성하지 않아도 된다는 장점
- SQL Server에서는
AS키워드 다음에 수행할 계산을 정의하는 표현식을 붙일 수 있음
- 결정적 (Dterministic) 함수: 특정 값 집합이 입력되면 언제나 동일한 결과를 반환
비결정적 (Nondterministic) 함수: 특정 값 집합이 입력되더라도 매번 다른 값을 반환할 수 있음
- 테이블을 정의할 때, 계산 컬럼을 정의할 수 있지만, 성능을 고려해야 함
- 트리거를 사용하여 계산 컬럼을 일반 컬럼처럼 정의할 수 있지만, 작성해야 할 코드가 복잡함
- 계산 컬럼은 DB 시스템에 추가적인 부하를 일으키므로 득과 실을 따져서 사용해야 함
Better way 6 - 참조 무결성을 보호하려면 외래키를 정의하자
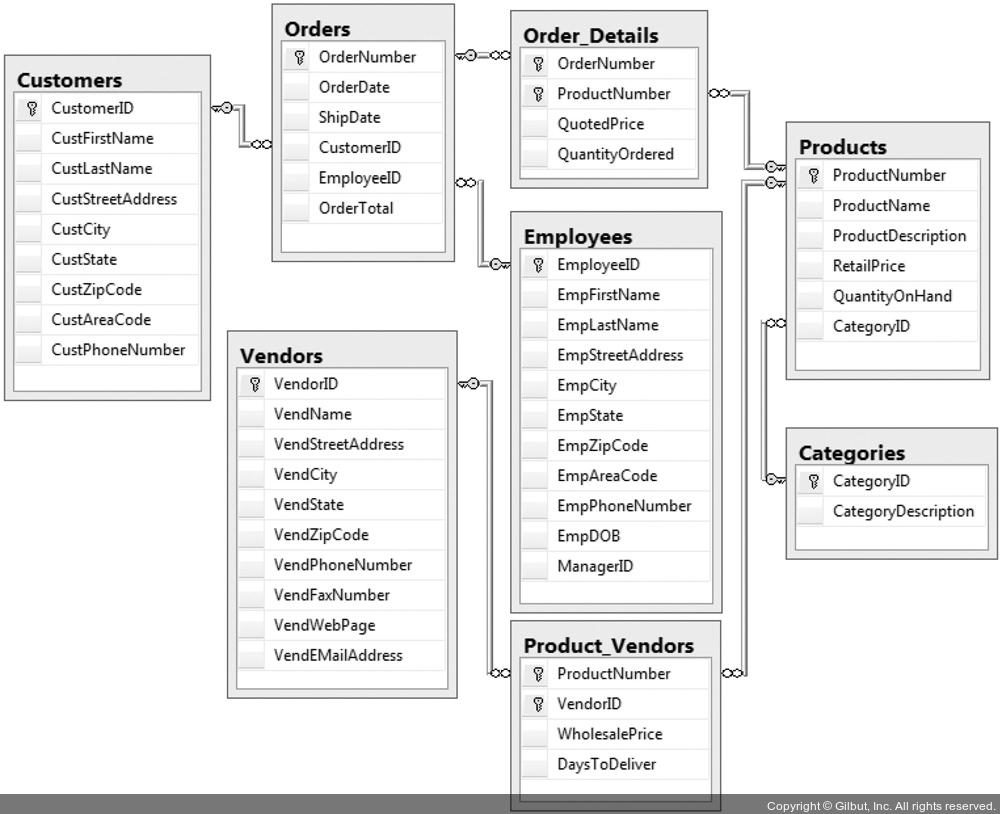
- DB 스키마를 제대로 설계하려면 관련된 부모 테이블의 기본키를 포함하도록 테이블에 외래키를 정의하는 것이 좋음
- Orders 테이블은 Customers 테이블의 기본키를 가리키는 CustomerID 컬럼을 정의하여 고객 정보 식별 가능
- 위 사진에서 각 관계선 끝에 위치한 열쇠 기호는 한 테이블의
기본키와 관계를 맺고 있음을 의미 반대편 끝에 있는 무한대 기호는 두 번째 테이블의
외래키와 일대다 관계를 맺고 있음을 의미- 선언적 참조 무결성 (Declarative Referential Integrity, DRI)을 정의하여 DB 시스템은 테이블 간 관계를 알고 있음
- 일대다 관계에서 ‘다’에 해당하는 테이블에 데이터를 입력, 변경하거나 ‘일’에 해당하는 테이블의 데이터를 변경, 삭제할 때, 데이터베이스 시스템이 데이터 무결성을 강화하는데 도움을 줌
- 일부 DB 시스템에서는 참조 무결성 제약 조건을 정의하면 자동으로 외래키 컬럼에 인덱스를 만듦
- 조인을 수행할 떄 성능 향상 효과가 있음
- 외래키 컬럼에 자동으로 인덱스가 만들어지지 않는다면, 따로라도 만드는게 좋음
Better way 7 - 테이블 간 관계를 명확히 하자
출처: SQL 코딩의 기술 책 리뷰